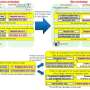
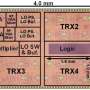
Figure1: Time Domain Neural Network
Toshiba Corporation continues to build on its commitment to promoting the Internet of Things and Big Data analysis with development of a Time Domain Neural Network (TDNN) that sues an extremely low power consumption neuromorphic semiconductor circuit to perform processing for Deep Learning. TDNN is composed of a massive number of tiny processing units that use Toshiba's original analog technique, unlike conventional digital processors. TDNN was reported on November 8 at A-SSCC 2016 (Asian Solid-State Circuits Conference 2016), an IEEE-sponsored international conference on semiconductor circuit technology held in Japan.
Deep learning requires massive numbers of calculations, typically executed on high performance processors that consume a lot of power. However, bringing the power of deep learning to IoT edge devices, such as sensors and smart phones requires highly energy efficient ICs that can perform the large number of required operations while consuming extremely little energy.
In von Neumann type computer architecture, most energy is consumed moving data from on-chip or off-chip memory devices to the processing unit. The most effective way to reduce movement of a datum is to have massive numbers of processing units, each dedicated to handling only one datum that is located close by. These datum points are given a weight during conversion of an input signal (e.g. an image of a cat) to an output signal (e.g. the recognition of the image as a cat). The closer the datum point is to the desired output, the higher the weight it is given. The weight provides a parameter that automatically guides the deep learning process.
The brain has similar architecture, in that the strength of coupling between neurons (weight data) is built into synapses (processing units). In this case, synapses are connections between neurons and each has a different strength. That strength (weight) determines the signal that passes the connection. In this way, a synapse executes a kind of processing. This architecture, which can be called as fully spatially unrolled architecture, is attractive, but it has an obvious drawback—replicating it on a chip requires a massive number of arithmetic circuits that quickly becomes too large.
Toshiba's TDNN, which employs time-domain analog and digital mixed signal processing (TDAMS) techniques developed in 2013 allow miniaturization of the processing unit. In TDAMS, arithmetic operations, such as addition, are performed efficiently by using the delay time of the digital signal passing the logic gate as an analog signal. Using this technique, the processing unit for deep learning can be composed of only three logic gates and a 1-bit memory with the fully spatially unrolled architecture. Toshiba has fabricated a proof-of-concept chip that uses SRAM (static random access memory) cell as the memory and that has demonstrated recognition of handwritten figures. The energy consumption per operation is 20.6 fJ, which is 1/6x better than previously reported at a leading conference before.
Toshiba plans to develop TDNN as a resistive random access memory (ReRAM) in order to further improve energy and area efficiencies. The goal is an IC that realizes high performance deep learning technology on edge devices.
Provided by Toshiba Corporation