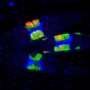
This map shows the predicted levels of risk to more than 150,000 species of plants located worldwide. Using vast amounts of open-access data, the researchers trained a machine learning algorithm to assign a probability that a given species would qualify for at-risk designation on the International Union for the Conservation of Nature's Red List of Threatened Species. Warmer colors denote areas with larger numbers of potentially at-risk species, while cooler colors denote areas with low overall predicted risk. Credit: Anahí Espíndola and Tara Pelletier
The International Union for Conservation of Nature's (IUCN) Red List of Threatened Species is a powerful tool for researchers and policymakers working to stem the tide of species loss across the globe. But adding even a single species to the list is no small task, demanding countless hours of expensive, rigorous and highly specialized research.
As a result of these limitations, a large number of known species have not yet been formally assessed by the IUCN and ranked in one of five categories, from least concern to critically endangered. This deficit is quite apparent in plants: Only about 5 percent of all currently known plant species appear on IUCN's Red List in any capacity.
A new method co-developed by Anahí Espíndola, an assistant professor of entomology at the University of Maryland, uses the power of machine learning and open-access data to predict species that could be eligible for at-risk status on the IUCN Red List. The research team created and trained a machine learning algorithm to assess more than 150,000 species of plants from all corners of the world, making their project among the largest assessments of conservation risk to date. According to the results, more than 10 percent of these species are highly likely to qualify for an at-risk IUCN classification.
The algorithm is a predictive model that can be applied to any grouping of species at any scale, from the entire globe to a single city park. Espíndola and her colleagues published their findings online in the Proceedings of the National Academy of Sciences on December 3, 2018.
"Our method isn't meant to replace formal assessments using IUCN protocols. It's a tool that can help prioritize the process, by calculating the probability that a given species is at risk," Espíndola said. "Ultimately, we hope it will help governments and resource managers decide where to devote their limited resources for conservation. This could be especially useful in regions that are understudied."
Espíndola and her collaborators built their predictive model using open-access data from the Global Biodiversity Information Facility (GBIF) and the TRY Plant Trait Database. Lead author Tara Pelletier, an assistant professor of biology at Radford University, worked together with Espíndola to perform the machine learning analysis.
Espíndola and Pelletier then trained the model using GBIF and TRY data from the relatively small group of plant species already on the IUCN Red List. This allowed the researchers to assess and fine-tune the model's accuracy by checking its predictions against the listed species' known IUCN risk status. The Red List sorts non-extinct species into one of five classification categories: least concern, near-threatened, vulnerable, endangered and critically endangered.
The researchers then applied the model to the many thousands of plant species that remain unlisted by IUCN. According to the results, more than 15,000 of the species—roughly 10 percent of the total assessed by the team—have a high probability of qualifying as near-threatened, at a minimum.
Espíndola and her colleagues mapped the data and noted several major geographical trends in the model's predictions. At-risk species tended to cluster in areas already known for their high native biodiversity, such as the Central American rainforests and southwestern Australia. The model also flagged regions such as California and the southeastern United States, which are home to a large number of endemic species, meaning that these species do not naturally occur anywhere else on Earth.
"When I first started thinking about this project, I suspected that many regions with high diversity would be well-studied and protected. But we found the opposite to be true," Espíndola said. "Many of the high-diversity areas corresponded to regions with the highest probability of risk. When we saw the maps, we were surprised it was that clear. Endemic species also tend to be more at risk because they are usually confined to smaller areas."
The model also flagged a few surprising areas not typically known for their biodiversity, such as the southern coast of the Arabian Peninsula, as having a high number of at-risk species. Some of the most imperiled regions have not received enough attention from researchers, according to Espíndola. She hopes that her method can help to fill in some of these knowledge gaps by identifying regions and species in need of further study.
"Let's say you wanted to assess every species of wild bee on one continent. So you do the assessment and find that only one species is at risk. Now you've used all those resources to identify an area with low risk, which is still helpful, but not ideal when resources are limited. We want to help prevent that from happening," Espíndola said. "Our analysis was global, but the model can be adapted for use at any geographic scale. Everything we've done is 100 percent open access, highlighting the power of publicly-available data. We hope people will use our model—and we hope they point out errors and help us fix them, to make it better."
The research paper, "Predicting plant conservation priorities on a global scale," Tara Pelletier, Bryan Carstens, David Tank, Jack Sullivan and Anahí Espíndola, was published online in the Proceedings of the National Academy of Sciences on December 3, 2018.
More information: Tara A. Pelletier el al., "Predicting plant conservation priorities on a global scale," PNAS (2018). www.pnas.org/cgi/doi/10.1073/pnas.1804098115
Journal information: Proceedings of the National Academy of Sciences
Provided by University of Maryland