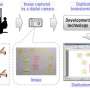
Text written on signs captured within video frames can now be detected and extracted using software that will make video footage searchable. © Hemera Technologies/AbleStock.com/Thinkstock
As video recording technology improves in performance and falls in price, ever-more events are being captured within video files. If all of this footage could be searched effectively, it would represent an invaluable information repository. One option to help catalogue large video databases is to extract text, such as street signs or building names, from the background of each recording. Now, a method that automates this process has been developed by a research team at the National University of Singapore, which also included Shijian Lu at the A*STAR Institute for Infocomm Research.
Previous research into automated text detection within images has focused mostly on document analysis. Recognizing background text within the complex scenes typically captured by video is a much greater challenge: it can come in any shape or size, be partly occluded by other objects, or be oriented in any direction.
The multi-step method for automating text recognition developed by Lu and co-workers overcomes these challenges, particularly the difficulties associated with multi-oriented text. Their method first processes video frames using 'masks' that enhance the contrast between text and background. The researchers developed a process to combine the output of two known masks to enhance text pixels without generating image noise. From the contrast-enhanced image, their method then searches for characters of text using an algorithm called a Bayesian classifier, which employs probabilistic models to detect the edges of each text character.
Even after identifying all characters in an image, a key challenge remains, explains Lu. The software must detect how each character relates to its neighbors to form lines of text—which might run in any orientation within the captured scene. Lu and his co-workers overcame this problem using a so-called 'boundary growing' approach. The software starts with one character and then scans its surroundings for nearby characters, growing the text box until the end of the line of text is found. Finally, the software eliminates false–positive results by checking that identified 'text boxes' conform to certain geometric rules.
Tests using sample video frames confirmed that the new method is the best yet at identifying video text, especially for text not oriented horizontally within the image, says Lu. However, there is still room for refinement, such as adapting the method to identify text not written in straight lines. "Document analysis methods achieve more than 90% character recognition," Lu adds. "The current state-of-the-art for video text is around 67–75%. There is a demand for improved accuracy."
More information: Shivakumara, P., Sreedhar, R. P., Phan, T. Q., Lu, S. & Tan, C. L. Multioriented video scene text detection through Bayesian classification and boundary growing. IEEE Transactions on Circuits and Systems for Video Technology 22, 1227–1235 (2012). dx.doi.org/10.1109/TCSVT.2012.2198129