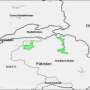
Map showing the inferred geographic origin of the Indo-European language family. The inferred point of origin is plotted in translucent red such that darker areas correspond to increased probability. The blue polygons delineate the proposed origin area under the Steppe hypothesis; dark blue represents the initial suggested Steppe homeland, and light blue denotes a later version of the Steppe hypothesis. The yellow polygon delineates the proposed origin under the Anatolian hypothesis. A green star in the steppe region shows the location of the centroid of the sampled languages. © MPI for Psycholinguistics
(Phys.org)—The Indo-European languages belong to one of the widest spread language families of the world. For the last two millenia, many of these languages have been written, and their history is relatively clear. But controversy remains about the time and place of the origins of the family. A large international team, including MPI researcher Michael Dunn, reports the results of an innovative Bayesian phylogeographic analysis of Indo-European linguistic and spatial data. Their paper 'Mapping the Origins and Expansion of the Indo-European Language Family' appeared this week in Science.
The majority view in historical linguistics is that the homeland of the Indo-European language family was located in the Pontic steppes (present day Ukraine) around 6000 years ago. The evidence for this comes from linguistic paleontology: in particular, certain words to do with the technology of wheeled vehicles are arguably present across all the branches of the Indo-European family; and archaeology tells us that wheeled vehicles arose no earlier than this date. The minority view links the origins of Indo-European with the spread of farming from Anatolia 8000-9500 years ago.

Maximum clade credibility tree for the 103 Indo-European languages in our sample. Branches are colored to indicate the main sub-families. The thickness of the branches reflects the relative rate of spatial diffusion along branches. Blue bars represent confidence intervals for the node ages. The gray density represents the estimate for the root age. All major nodes were supported by a posterior probability 0.95 except those indicated with a ‘*’. © MPI for Psycholinguistics
The minority view is decisively supported by the present analysis in this week's Science. This analysis combines a model of the evolution of the lexicons of individual languages with an explicit spatial model of the dispersal of the speakers of those languages. Known events in the past (the date of attestation dead languages, as well as events which can be fixed from archaeology or the historical record) are used to calibrate the inferred family tree against time.
The lexical data used in this analysis come from the Indo-European Lexical Cognacy Database (IELex). This database has been developed in MPI's Evolutionary Processes in Language and Culture group, and provides a large, high-quality collection of language data suitable for phylogenetic analysis. Beyond the intrinsic interest of uncovering the history of language families and their speakers, phylogenetic trees are crucially important for understanding evolution and diversity in many human sciences, from syntax and semantics to social structure.
More information: Remco Bouckaert, et al., Mapping the Origins and Expansion of the Indo-European Language Family, Science 24 August 2012: 337 (6097), 957-960. [DOI:10.1126/science.1219669]
Journal information: Science
Provided by Max Planck Society