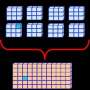
The redundant data distribution of an array showing that a node failure will leave at least one copy of the data available for continued execution. This is the basic idea that enables the approach, which can be used in many science domains.
(PhysOrg.com) -- Environmental Molecular Sciences Laboratory (EMSL) users have designed and implemented an efficient fault-tolerant version of the coupled cluster method for high-performance computational chemistry using in-memory data redundancy.
Their method, demonstrated with the EMSL-developed and now open source software NWChem, addresses the computational chemistry challenges of reduced mean time between failures, which is currently days and projected to be hours for upcoming extreme scale supercomputers.
Their approach with coupled cluster perturbative triples enables the program to correctly continue execution despite the loss of processes.
The team extended the Global Array toolkit, a library that provides an efficient and portable “shared-memory” programming interface for distributed-memory computers.
Each process in a Multiple Instruction/Multiple Data parallel program can asynchronously access logical blocks of physically distributed dense multidimensional arrays, without requiring cooperation by other processes.
The infrastructure that the team developed was shown to add an overhead of less than 10% and can be deployed to other algorithms throughout NWChem as well as other codes. Such advances in supercomputing will enhance scientific capability to address global challenges such as climate change and energy solutions using top-end computing platforms.
More information: van Dam HJJ, A Vishnu, and WA de Jong. 2011. “Designing a Scalable Fault Tolerance Model for High Performance Computational Chemistry: A Case Study with Coupled Cluster Perturbative Triples.” J. Chem. Theory Comput. 2011, 7, 66–75. DOI:10.1021/ct100439u
Provided by Pacific Northwest National Laboratory