The study of proteins (which are found throughout every cell and tissue in the body) is of specific interest to scientists, as they are an integral part of most biological processes. Proteins are composed of amino acids chemically linked together, while shorter stretches of amino acids are commonly referred to as peptides.
For some time, research has focused on looking for synthetic peptides in an attempt to identify or mimic biological targets. These peptides, and the molecules they interact with, are frequently the subject of life science research, and they are of considerable medical and pharmaceutical interest. However, the cost of peptide synthesis is a significant barrier to detailed analysis and further progress in this area.
However, this is set to change with the PEPCHIPOMICS project, which is supported by the Seventh Framework Programme for Research and Technological Development (FP7) of the European Union. PEPCHIPOMICS is aimed at synthesising and reading very high-density peptide microarrays.
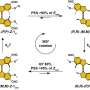
Developments in the PEPCHIPOMICS project have resulted in a new high-throughput platform, which integrates peptide synthesis, detection and analysis at an unprecedented scale. This peptide microarray technology can synthesise 2 million different peptides on a small slide the size of a stamp. This is enough to express the entire human proteome (the entire set of proteins expressed by a genome, cell tissue or organism) as overlapping peptides.
Coordinator of the project, Professor Søren Buus from the University of Copenhagen, explains: 'This technology allows us to represent large assemblies of proteins - say the entire human proteome - on a single slide. Or it allows us to examine smaller assemblies (even single targets) in great detail using many variants of the peptide of interest. These experiments have in the past been prohibitively expensive, and logistically very demanding. How do you keep track of say 100 000 targets, and the associated results? Now they have become less expensive and easier to handle. Scientist and industry can now use exhaustive peptide-based approaches (say representing the entire proteome) in their search for targets of scientific interest and their search for new lead candidates.'
Earlier in the year, the project made progress by finding that more than 100,000 peptides could be synthesised in parallel, with the capacity to detect the interaction of 'other molecules'. This research demonstrated the ability to interpret the data, as well as identify what these 'other molecules' recognised.
'But this is just the beginning,' says Professor Buus. 'The next goal is to integrate the peptide microarray technology with powerful label-free technologies that will detect the interaction between the peptide chip and any other molecules offered to the chip in real time allowing the on- and off-rates to be determined as well as the strength of the interaction - parameters that are of considerable interest in biotechnology, medicine and pharmacy. It could even be possible to identify which molecules interact with which peptides.'
The ability to address peptides at a level that matches the current genomics revolution could have a significant impact on how scientific and clinical questions are addressed in the future, and on how biotechnology and pharmaceutical problems can be solved.
Provided by CORDIS