Computational 'match game' identifies potential antibiotics

Computational biologists at Carnegie Mellon University have devised a software tool that can play a high-speed "Match Game" to identify bioactive molecules and the microbial genes that produce them so they can be evaluated as possible antibiotics and other therapeutic agents.
Working with colleagues at the University of California, San Diego, and six other institutions, Hosein Mohimani, an assistant professor in CMU's Computational Biology Department, and Liu Cao, a Ph.D. student in the department, demonstrated that their MetaMiner tool could identify bioactive molecules at least 100 times faster than was possible with previous methods.
The researchers discuss their findings—including their discovery of seven previously unknown molecules of biological interest from various environments like the human gut, the deep ocean and the International Space Station—in a research paper published today by the journal Cell Systems.
New techniques for obtaining the DNA of microbes directly from the environment has created intense interest in microbial communities, including those that coexist with healthy humans. Some microbes produce molecules that protect their host and, thus, are candidates to become therapeutic drugs. In the last decade, microbiologists have generated a number of large databases of microbe DNA.
But microbe communities consist of hundreds or thousands of different types of microbes—and millions of different molecular products—and each microbe tends to die quickly if removed individually for study. So identifying molecules that might be drug candidates and isolating the microbes that produce them requires some innovative thinking.
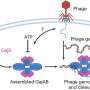
Cao and Mohimani decided to use an approach called genome mining. This involves looking at clusters of genes and attempting to infer what molecules these genes produce. It's much like looking at an auto assembly line and trying to determine what kind of car it can build, Mohimani said.
However, predicting the molecular product of a gene cluster is fraught with errors, Cao said. To work around this shortcoming, he and Mohimani borrowed a trick from electrical engineering, called Viterbi decoding, which helps engineers detect messages in a "noisy" radio channel. This enabled them to build an error-tolerant search engine that could find matches between databases of microbial DNA and databases that identify molecular products by their mass spectra.
Cao and Mohimani, working with microbiologists from multiple institutions, applied their methods to the discovery of ribosomally synthesized and post-translationally modified peptides (or RiPPs), a family of natural products that have found applications in pharmaceuticals and the food industry.
About 20,000 gene clusters that encode RiPPs have been discovered, but until now only a handful of RiPPs have been matched to one of those clusters. By using MetaMiner to search millions of molecular product spectra and compare them to the gene clusters in eight datasets, the researchers were able to identify 31 known RiPPs and seven previously unknown RiPPs—all in about two weeks.
"Normally, you'd be happy to find one match," Mohimani said. Obtaining these results with manual methods likely would take decades, he added.
Journal information: Cell Systems
Provided by Carnegie Mellon University