Team discovers enzyme domains that dramatically improve performance

It was more than 10 years in the making, but when it came to uncovering the secrets of the molecular structure of enzymes, perseverance paid off. By studying and comparing the workhorse cellulose-degrading enzymes of two fungi, researchers from the Energy Department's National Renewable Energy Laboratory (NREL) have pinpointed regions on these enzymes that can be targeted via genetic engineering to help break down cellulose faster.
Newly published in Nature Communications, "Engineering enhanced cellobiohydrolase activity" describes NREL's long-running study of the fungal cellobiohydrolases (CBHs)—enzymes that use hydrolysis as their main chemistry to degrade cellulose—Trichoderma reesei (TrCel7A) and Penicillium funiculosum (PfCel7A). Years of meticulous research have yielded big rewards: the team has gained a better understanding of the structure-activity relationships of these enzymes to predict the best places to make changes and improvements.
In both nature and industrial processes, enzymes from this family are among the most significant enzymes for breaking down cellulose. A projected 2,000-ton-per-day cellulosic ethanol plant could potentially use up to 5,000 tons of enzyme per year, and half of that enzyme cocktail could be from this enzyme family. "There's been a drive over the last several decades of trying to understand and improve biocatalysts from this key enzyme family," said Gregg Beckham, group leader at NREL and senior author of the study. "The more efficient the enzyme, the less enzyme used, and thus the process is cheaper. However, we still have a long way to go to be able to make enhancements in a predictive capacity."
Then, in 2005, NREL researchers Mike Himmel, Steve Decker, and Bill Adney discovered a CBH from a different fungus, PfCel7A, and found that it performs 60 percent better than TrCel7A. "It surprised us that this enzyme was so much better than the industry standard," said Decker, who lead the task after Adney left NREL. "We ran a lot of experiments over the past few years to be sure the activity was real. Then, of course, we wanted to know why it was better."
"If we could understand the structural differences, then we could potentially use that information to engineer better enzymes, which in turn could help reduce the cost of cellulosic biofuel and biochemical production," said Beckham. "Given the challenge working with these enzymes, it took NREL's team seven years of thorough experimental work to develop the tools needed to ascertain that there are a couple of hot spots on these two CBHs that can be modified to make them perform better."
According to Decker, "At the time, tools for genetic engineering in Trichoderma were very limited, but we knew from previous work that other hosts had issues expressing these proteins. We basically started from scratch and built our own in-house T. reesei system of host strains, vectors, and transformation and screening protocols. Compared to well-developed systems like E. coli, T. reesei's poor transformation efficiency, tedious selection processes, slow growth, and low protein yield made this a challenging operation. Every strain we built took months from design to final testing."
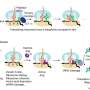
The discovery unfolded as NREL took a close look at the similarities between TrCel7A and PfCel7A and then worked to isolate the differences. Both enzymes have a three-domain architecture: the carbohydrate binding molecule that attaches it to cellulose; the catalytic domain that breaks down cellulose; and the link that connects these two domains together. The research team then conducted domain swapping experiments by creating a chimera library, which is a collection of mutant enzymes created from the two parent enzymes.
"With three domains between two parents, that makes eight combinations in total," said Beckham. "We tested the various combinations to find out which area is providing the enzyme with better performance, and perhaps not surprisingly, in hindsight, it's the catalytic domain."
With those findings, the researchers then compared the catalytic domains of TrCel7A and PfCel7A and found eight areas that were different. Continuing to narrow down the possibilities, the team took the TrCel7A parent and made modifications, one at a time, in those eight areas and uncovered two important modifications that resulted in TrCel7A performing almost to the level of the PfCel7A parent.
"Those two, very small changes on this huge protein basically doubled the performance of TrCel7A," said Beckham. "What this teaches researchers doing protein engineering on these incredibly challenging enzymes is that there are very minor changes to this catalytic domain that can be modified to dramatically affect the performance of the enzyme, making it capable of breaking down cellulose faster and thus allowing industrial processes to use less enzyme."
"We knew that the discovery of PfCel7A was important at the time, but the pathway forward was not entirely clear," said Himmel, the overall project leader. "We tackled the most difficult family of cellulases to improve first, and so it follows that biomass-degrading enzymes from other families can be rendered maximally active in a more streamlined process, with less research and development. It was the melding of experimental biochemistry and computational science that brought this study to Nature Communications and that result was only possible with sustained funding from the Bioenergy Technologies Office."
The NREL team's ultimate aim is to help other researchers sift through the mountain of genomics data to find better enzymes, based on their genetic sequence alone. "In 10 years, it would be so exciting to be able to sit down with thousands of enzyme sequences from this family and be able to predict which few to try," said Beckham. "This study is one step on a very long road, but it's a worthy goal."
More information: Engineering enhanced cellobiohydrolase activity, Nature Communications, volume 9, Article number: 1186 (2018) DOI: 10.1038/s41467-018-03501-8 , www.nature.com/articles/s41467-018-03501-8
Journal information: Nature Communications
Provided by National Renewable Energy Laboratory