A new machine learning based intention detection method using first-person-view camera for Exo Glove Poly II

A Korean research team has proposed a new paradigm for a wearable hand robot that can aid people with lost hand mobility. The hand robot collects user behaviors with a machine learning algorithm to determine the user's intention.
Professor Sungho Jo (KAIST) and Kyu-Jin Cho (Seoul National University) have proposed a new intention-detection paradigm for wearable hand robots. The proposed paradigm predicts grasping/releasing intentions based on user behaviors, enabling spinal cord injury (SCI) patients with lost hand mobility to pick and place objects.
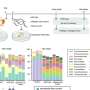
They developed the method based on a machine learning algorithm that predicts user intentions via a first-person-view camera. Their development is based on the hypothesis that user intentions can be inferred through the collection of user arm behaviors and hand-object interactions.
The machine-learning model used in this study, Vision-based Intention Detection network from an EgOcentric view (VIDEO-Net), is designed based on this hypothesis. VIDEO-Net is composed of spatial and temporal sub-networks, which recognize user arm behaviors, and a spatial sub-network that recognizes hand-object interactions.
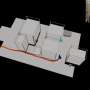
An SCI patient wearing Exo-Glove Poly II, a soft wearable hand robot, successfully picked and placed various objects and performed essential activities of daily living, such as drinking coffee, without any additional help.
This development is advantageous in that it detects user intentions without requiring any person-to-person calibrations or additional actions. This enables a human to use the wearable hand robot seamlessly.
Interview with Professor Kyu-Jin Cho
Q: How does this system work?
A: This technology aims to predict user intentions, specifically grasping and releasing intent toward a target object, by utilizing a first-person-view camera mounted on glasses. VIDEONet, a deep learning-based algorithm, is devised to predict user intentions from the camera based on user arm behaviors and hand-object interactions. Instead of using bio-signals, which is often used for intention detection of disabled people, we use a simple camera to find out whether the person is trying to grasp or not. This works because the target users are able to move their arm, but not their hands. We can predict the user's intention of grasping by observing the arm movement and the distance from the object and the hand, and interpreting the observation using machine learning.
Q: Who benefits from this technology?
A: As mentioned earlier, this technology detects user intentions from human arm behaviors and hand-object interactions. This technology can be used by anyone with lost hand mobility due to spinal cord injury, stroke, cerebral palsy or any other condition, as long as they can move their arm voluntarily.
Q: What are the limitations and future works?
A: Most of the limitations come from the drawbacks of using a monocular camera. For example, if a target object is occluded by another object, the performance of this technology decreases. Also, if user hand gesture is not able to be seen in the camera scene, the technology is not usable. In order to overcome the lack of generality due to these issues, the algorithm needs to be improved by incorporating other sensor information or other existing intention detection methods, such as using an electromyography sensor or tracking eye gaze.
Q: To use this technology in daily life, what do you need?
A: In order for this technology to be used in daily life, a user needs a wearable hand robot with an actuation module, a computing device, and glasses with a camera mounted. We aim to decrease the size and weight of the computing device so that the robot can be portable to be used in daily life. We used a compact computing device that fulfills our requirements, but we expect that neuromorphic chips that are able to perform deep learning computations will be commercially available.
More information: D. Kim el al., "Eyes are faster than hands: A soft wearable robot learns user intention from the egocentric view," Science Robotics (2019). robotics.sciencemag.org/lookup … /scirobotics.aav2949
Journal information: Science Robotics
Provided by Seoul National University