Distributing control of deep learning training delivers 10x performance improvement

My IBM Research AI team and I recently completed the first formal theoretical study of the convergence rate and communications complexity associated with a decentralized distributed approach in a deep learning training setting. The empirical evidence proves that in specific configurations, a decentralized approach can result in a 10x performance boost over a centralized approach without additional complexity. A paper describing our work has been accepted for oral presentation at the NIPS 2017 Conference, one of the 40 out of 3240 submissions selected for this.
Supervised machine learning generally consists of two phases: 1) training (building a model) and 2) inference (making predictions with the model). The training phase involves finding optimal values for a model's parameters such that error on a set of training examples is minimized, and the model generalizes to new data. There are several algorithms to find optimal values (training cost vs. model accuracy) for model parameters, however, gradient decent, in various flavors, is one of the most popular.
In its simplest form, gradient descent is a serial algorithm that iteratively tweaks a model's parameters and, therefore, is prohibitively expensive for large datasets. The Stochastic Gradient Descent (SGD) is a computational simplification which cycles through the training samples in random order to arrive at optimal parameter values (convergence). In fact, SGD is the de facto optimization method used during model training for most of the deep learning frameworks. Accelerating solving for the SGD can help lower training costs and improve overall user experience, and is one of the important fields of study in the deep learning domain.
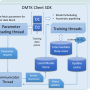
The Parallel Stochastic Gradient Descent (PSGD) is an approach to parallelize the SGD algorithm by using multiple gradient calculating "workers." The PSGD approach is based on the distributed computing paradigm and, until recently, has been implemented in a centralized configuration arrangement to deal with challenges involved in consistent reads of and updates to model parameters. In such a configuration, there is, conceptually, a single centralized "master" parameter server responsible for synchronized reading and updating. Two of the most commonly used centralized PGSD approaches are all-reduce and asynchronous SGD (ASGD).
During the past three years, I have been studying and working on the all-reduce based approach, and designing and testing several protocol variants for ASGD. The two approaches have unique pros and cons. The all-reduce approach has predictable convergence, but, being synchronous, is slow. The ASGD-based approach allows workers to run at different speeds (without synchronization) and is fast, but has unpredictable convergence behavior. In practice, depending upon the approach taken, you are either praying that there is no computing device hiccup so the all-reduce runtime is not abysmal; or hoping the ASGD algorithm will just converge, keeping the accuracy vs training cost curve in-check.
It took me about two and a half years of work to realize that both approaches are essentially the same – centralized configurations. The only difference is that in all-reduce, there is one version of the central weights and, in ASGD, there are multiple versions. In any case, the centralized parameter server, unfortunately, becomes the single point of failure and a runtime bottleneck for both.
The obvious question then was, what if we can get rid of the parameter server altogether and let each worker run in a peer-to-peer fashion and, eventually, reach a consensus? If it worked, it would simplify distributed deep learning system design tremendously – not only could we get rid of the single point of failure, but also reduce the training cost. However, nobody knew if such a decentralized distributed approach would generate correct results for complicated optimization problems such as deep learning training.
To our surprise and delight, we have found that our approach works and can achieve similar convergence rates as the traditional SGD. Our solution has been successfully applied to deep learning training across different type of workloads (open-source workloads and proprietary IBM workloads) and is easy to incorporate into various open-source frameworks (already accomplished for Torch). The technique works extremely well in slow network configurations as it involves a low volume of handshake messages.
Provided by IBM