Crowdsourcing effort helps researchers predict how a molecule will smell

You can anticipate a color before you see it, based solely on the length of light waves. Music can be interpreted from notes on a page without being heard. Not so with odor. The only way to tell if something will smell like roses or turpentine, sea breeze or gasoline, is to sniff it.
New research, described in Science on February 24, is making the most mysterious of our senses a little more predictable. A project initiated by Rockefeller University scientists and powered by a crowdsourcing effort has devised a mathematical model that can forecast the scent a molecule will evoke.
"This is a centuries-old problem. People have attempted to work around it in many different ways, as you can see in the perfume section of a department store, when the clerks ask 'do you like something floral?' or 'do you like something musky?'" says study researcher Leslie Vosshall, the Robin Chemers Neustein Professor.
"We haven't completely solved the question of how to predict an odor based on the chemical properties of the molecules that convey it, but this is the furthest anyone has pushed toward an explanation," she adds.
The good, the bad, and the odorless
As head of Rockefeller's Laboratory of Neurogenetics and Behavior, Vosshall studies odor perception in humans and insects. As part of this work, she and Andreas Keller, a research associate in her lab, set out to explore the link between molecules and the scent they give off.
To get the data they needed, they asked volunteers to sniff a carefully curated set of molecules, each contained in a little vial. The possibilities were nearly endless—while the limits on human perception of light and sound are well known, no such boundaries have been established for odor. So in an effort to explore the full range of our sense of smell, Keller assembled a diverse cast of 476 molecules, many of which had never been tested in smell studies before.
He included familiar aromas, like the sweet warmth of vanillin and the reek of methylthiobutyrate, a stinky-cheese molecule. He also selected molecules sniffers were unlikely to recognize—2-isopropylphenol, anyone?—and even those thought to be odorless, like water and glycerol. The 49 study volunteers rated each based on how strong they found it, how pleasant, and to what degree it evoked garlic, flower, urine, and 16 other attributes.
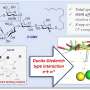
Altogether, this effort generated more than 1 million data points. The researchers then sought to link this perceptual information to more than 2 million additional data points describing chemical features of the smell molecules, such as the number of sulfur atoms they contain. It took a crowd to solve this problem.
A community effort
Twenty-two teams of computationally savvy volunteers hailing from research institutions and companies around the world participated in the DREAM Olfaction Prediction Challenge, which was organized by study researcher Pablo Meyer, a team leader at IBM's Thomas J. Watson Research Center. Using Vosshall's and Keller's odor ratings, one of the largest sets of such data ever collected, these teams devised algorithms that could "learn" to predict an odor's attributes based on a molecule's chemical features.
The best solution didn't appear in any single model. To take advantage of the wisdom of the crowd, DREAM challenges typically merge their submissions into an aggregate model, one that is often more powerful than any individual model.
"A DREAM Challenge is more like hitting a piñata at a party than a normal research project: Everyone swings, and even if your algorithms don't break it open, you still contribute to the solution," Meyer says. "With this approach, a robust set of data, and a little luck, we were able to crack this particularly difficult problem."
Filling in the gap
At the end of the challenge, the researchers tested the performance of the aggregate model using ratings they had held back on 69 molecules as a sort of answer key. A perfect score for matching attribute profiles to molecules would have been 1.0; the model scored 0.83, significantly better than any previous attempts to solve this problem.
The smells that the models could most easily predict were garlic and fish, probably because the sniffers generally agreed on how to apply them while rating odors. Other attributes, such as cold or acid, were more challenging, probably because there is less consensus about what these terms mean for an odor, Vosshall says.
While not yet perfect, the smell prediction model opens new possibilities for perfume chemists looking for more efficient ways to formulate, say, the perfect scent of dusky rose. It also shines new light on the immensely complex biology of smell perception. No one fully understands what happens when odor molecules waft into the nose and are converted into electrical signals that travel to the brain.
"Once you can associate the input of the chemical structure and the output of an odor, you can start to delineate what might be happening during that translation," says Vosshall who is a Howard Hughes Medical Institute investigator. "This model is an important initial step in that direction."
More information: Predicting human olfactory perception from chemical features of odor molecules. Science. DOI: 10.1126/science.aal0787
Journal information: Science
Provided by Rockefeller University