April 22, 2013 report
Adapteva $99 parallel processing boards targeted for summer

(Phys.org) —The semiconductor technology company Adapteva earlier this month featured its parallel-processing board for Linux supercomputingts at a major Linux event, and the board is targeted to ship this summer. The board will be going out to those who pledged money in last year's Adapteva Kickstarter campaign and to other customers. Not a minute too soon. To hear the story of computing as Adapteva tells it, the future of computing is parallel. Big-data and other demands pose a processor challenge and Adapteva recognizes a problem in energy efficiency that is calling for action. Adapteva is on a mission to "democratize" access to parallel computing.
The processor board running on Linux is called Parallella. According to the Kickstarter page, pledges totaled $898,921 from 4,965 backers when Adapteva set its goal for funding. The company decided to go through the crowdfunding route in order to produce the Parallella boards in volume. They sought funding for adequate tooling to accommodate volume, to make this board effort viable, to get the platform "out there."
The company's hurry-up drive on making parallel processing access easier for more people has a sense of urgency because the company wants to speed adoption of parallel processing in the industry. Founded in 2008, the company's chip technology has gained traction with government labs, corporate labs, and schools but getting large corporations to buy into parallel computing is challenging. They were convinced that the only way to create a sustainable parallel computing platform was through a grass roots movement. The company founder, Andreas Olofsson, said that parallel computing is the only way to scale to energy efficiency, performance, and cost. Systems, he stated, need to be parallel and they need to be open "Our 99 dollar kit is going to be completely open," he said, and the Parallella open platform will educate the masses on how to do parallel computing.
"We don't have time to wait for the rest of the industry to come around to the fact that parallel computing is the only path forward and that we need to act now. We hope you will join us in our mission to change the way computers are built," they had said when appealing earlier for support.
The Lexington, Massachusetts, company has now announced they built the first Parallella board for Linux supercomputing. They made the announcement at the Linux Collaboration Summit in San Francisco earlier this month. (The summit is a gathering of core kernel developers, distribution maintainers, ISVs, end users, system vendors and various other community organizations.) The Linux distribution being used is Ubuntu 12.04
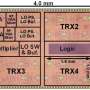
Adapteva's board is the size of a credit card. This comes with a dual-core ARM A9 processor and a 64-core Epiphany Multicore Accelerator chip. Parallela's details include 1GB of RAM, two USB 2.0 ports, a microSD slot, and an HDMI connection. Active components and the majority of the standard connectors are on the top side of the board. The expansion connectors and microSD card connector are at the bottom side of the board.
Olofsson said the company's first audience target is developers. "We need to make sure that every programmer has access to cheap and open parallel hardware and development tools," said an Adapteva program note for the Linux event. Massively parallel computing will become truly ubiquitous once the vast majority of programmers and programs know how to take full advantage of the underlying hardware They see a critical need to close the knowledge gap in parallel programming. They said their targeted our second tier are the people who just want an awesome computer for $99.
Platform reference design and drivers are now available.
More information:
www.parallella.org/2013/04/02/ … a-hardware-platform/
www.parallella.org/2013/04/16/ … -name-is-parallella/
© 2013 Phys.org