September 12, 2019 report
Chemists show how bias can crop up in machine learning algorithm results
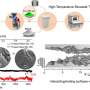
 or failure (outcomes 1, 2 and 3) for a given amine, for the N = 27 popular and N = 28 not-popular amines among the human-selected dataset. Centre values indicate observed proportion of outcomes. Error bars indicate a bootstrap estimate of the standard deviation. Credit: Nature (2019). DOI: 10.1038/s41586-019-1540-5")
A team of material scientists at Haverford College has shown how human bias in data can impact the results of machine-learning algorithms used to predict new reagents for use in making desired products. In their paper published in the journal Nature, the group describes testing a machine-learning algorithm with different types of datasets and what they found.
One of the more well-known applications of machine-learning algorithms is in facial recognition. But there are possible problems with such algorithms. One such problem occurs when a facial algorithm intended to look for an individual among many faces has been trained using people of just one race. In this new effort, the researchers wondered if bias, unintentional or otherwise, might be cropping up in machine learning algorithm results used in chemistry applications designed to look for new products.
Such algorithms use data describing the ingredients of reactions that result in the creation of a new product. But the data the system is trained on could have a major impact on the results. The researchers note that currently, such data is obtained from published research efforts, which means they are typically generated by humans. They note that the data from such efforts could have been generated by the researchers themselves, or by other researchers working on separate efforts. Data could even come from a single person simply relating from memory, or from a professor's suggestion, or a graduate student with a bright idea. The point is, the data could be biased in terms of the background of the resource.
In this new effort, the researchers wanted to know if such biases might have an impact on the results of machine-learning algorithms used for chemistry applications. To find out, they looked at a specific set of materials called amine-templated vanadium borates. When they are synthesized successfully, crystals form—an easy way to determine if a reaction was successful.
The experiment consisted of training a machine-learning algorithm on data surrounding the synthesis of vanadium borates, and then programming the system to create its own. Some of the data collected by the researchers was human-generated, and some of it was collected randomly. They report that the algorithm trained on the random data did better at finding ways to synthesize the vanadium borates than when it used data generated from humans. They claim this shows a clear bias in the data that was created by humans.
More information: Xiwen Jia et al. Anthropogenic biases in chemical reaction data hinder exploratory inorganic synthesis, Nature (2019). DOI: 10.1038/s41586-019-1540-5
Journal information: Nature
© 2019 Science X Network