Moving big data faster, by orders of magnitude
In today's high-productivity computing environments that process dizzying amounts of data each millisecond, a research project named for "a trillion events per day" may seem relatively ordinary.
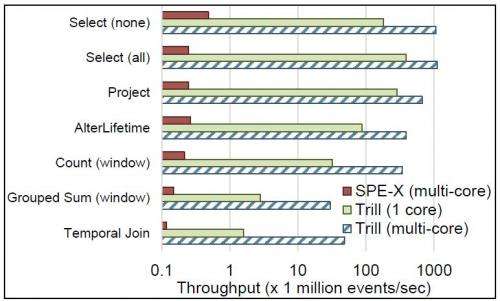
But when you understand that Trill, a new high-performance streaming analytics engine developed by Microsoft researchers, can process data at two to four orders of magnitude faster than today's streaming engines, well, now you're getting into "wow" territory, especially considering Trill is just a .NET library:
- As a single-node engine library, any .NET application, service, or platform can easily include it and start processing queries;
- A temporal query language allows users to express complex queries over real-time and/or offline data sets; and,
- Trill's high performance across intended usage scenarios means users can get results significantly faster than before.
"Prior systems have only achieved subsets of these benefits, but Trill provides all of these advantages in one package, so to speak." says Badrish Chandramouli, one of the Microsoft researchers who developed Trill.
Its secret? Trill incorporates new techniques and algorithms that process events in batches, with the data within those batches organized in new ways that enable queries to execute much more efficiently than before, but to users it's the same as working with a .NET library—no need to leave the .NET environment.
Bing Ads customers, in fact, already are enjoying the paradigm shift, seeing results in less than an hour of launching Bing ad campaigns.
And it doesn't end there.
"While it can be integrated into today's distribution fabrics such as SCOPE (in Bing ads) and Orleans (in Halo) to achieve scale-out, we are currently looking at developing new techniques to achieve even better performance in distributed computing and Internet-of-Things scenarios," Chandramouli says.
Started in early 2012 by Chandramouli and fellow researcher Jonathan Goldstein, and detailed in Trill: A High-Performance Incremental Query Processor for Diverse Analytics, its roots can be traced to earlier research in Complex Event Detection and Response algebra (CEDR), dating back to 2007, and published in Consistent Streaming Through Time: A Vision for Event Stream Processing. And in the interim, a successive paper that introduced the idea of using a single language and engine to handle real-time and offline datasets, Temporal Analytics on Big Data for Web Advertising, won Best-paper at IDCE 2012.
"From CEDR to Trill to multiple Microsoft products: This body of work is a great example of how within Microsoft Research we evolve from science to technology to business impact," says Jeannette Wing, Corporate Vice President, Microsoft Research. "It also shows the nature and value of long-term research, where patience and persistence really pay off."
While not directly available to the public, Trill also is being used elsewhere at Microsoft, as a query processor within the Azure Stream Analytics service, currently under public preview. Additional collaborators on Trill include: Mike Barnett, Rob DeLine, Danyel Fisher, John Platt, James Terwilliger, and John Wernsing.
More information: Trill: A High-Performance Incremental Query Processor for Diverse Analytics: research.microsoft.com/pubs/23 … 0/trill-vldb2015.pdf
Consistent Streaming Through Time: A Vision for Event Stream Processing: research.microsoft.com/pubs/156569/cidr07p42.pdf
Temporal Analytics on Big Data for Web Advertising: research.microsoft.com/apps/pu … fault.aspx?id=155806
Provided by Microsoft