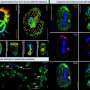
Performance of facial recognition software continues to improve
 in a large collection of 1.6 million \"known\" images. Credit: NIST")
Who is that stranger in your social media photo? A click on the face reveals the name in seconds, almost as soon as you can identify your best friend. While that handy app is not quite ready for your smart phone, researchers are racing to develop reliable methods to match one person's photo from millions of images for a variety of applications. The National Institute of Standards and Technology (NIST) reports that results from its 2013 test of facial recognition algorithms show that accuracy has improved up to 30 percent since 2010.
The report by NIST biometric researchers Patrick Grother and Mei Ngan, Performance of Face identification Algorithms,* includes results from algorithms submitted by 16 organizations. Researchers defined performance by recognition accuracy—how many times the software correctly identified the photo—and the time the algorithms took to match one photo against massive photo data sets.
"We studied the one-to-many identification because it is the largest market for face recognition technology," Grother said. "These algorithms are used around the world to detect duplicates in databases, fraudulent applications for passports and driving licenses, in token-less access control, surveillance, social media tagging, lookalike discovery and criminal investigations."
Four research groups enrolled in both the 2013 and the previous 2010 test,** allowing NIST researchers to compare performance improvements over time. They found that those groups had improved their performance on the tests by from 10 and almost 30 percent. One organization decreased its error rate from 8.9 percent in 2010 to 6.4 percent in 2013.
In both years the study used a database of 1.6 million faces. In 2010, the images were frontal "mugshot" images from law enforcement agencies that closely comply with the ANSI/NIST ITL 1-2011 Type 10 standard. In 2013, researchers added a small database of images taken for visa applications that meet an ISO/IEC (International Organization for Standardization/International Electrotechnical Commission) standard and 140,000 webcam images taken in poorly controlled environments that do not comply with any standard.
The tested algorithms performed the best on the relatively high-quality ISO standardized images collected for passport, visa and driving license applications. Detecting duplicates in those applications is the biggest segment of the face recognition marketplace. No algorithms worked well with the webcam images. Search failure rates for those images were around three times greater than for the higher quality images.
The study also shows that rates of missing facial matches increase as the database size increases as expected, but that it does so only slowly. When the number of facial images increased by a factor of 10—from 160,000 to 1.6 million—the error rate only increased by about 1.2 times. This slower-then-expected growth in error rates occurs in many natural phenomenon, and "is largely responsible for the operational utility of face identification algorithms," explains Grother.
Images of older individuals were identified more accurately than those of younger persons, suggesting that we become steadily easier to recognize using facial recognition software, and more distinguishable from our contemporaries, as we age.
More information: * P. Grother and M. Ngan. Performance of Face identification Algorithms (NIST Interagency Report 8009). May 2014. Available at www.nist.gov/manuscript-public … ch.cfm?pub_id=915761
** P. Grother, G.W. Quinn and P.J. Phillips. Report on the Evaluation of 2D Still-Image Face Recognition Algorithms (NIST Interagency Report 7709). August 2011. Available at www.nist.gov/manuscript-public … ch.cfm?pub_id=905968
Provided by National Institute of Standards and Technology