Research uncovers new exception to decades-old rule about RNA splicing
There are always exceptions to a rule, even one that has prevailed for more than three decades, as demonstrated by a Cold Spring Harbor Laboratory (CSHL) study on RNA splicing, a cellular editing process. The rule-flaunting exception uncovered by the study concerns the way in which a newly produced RNA molecule is cut and pasted at precise locations called splice sites before being translated into protein.
"The discovery of this exception could impact current ideas on how missteps in splicing triggered by mutations in the DNA sequence can lead to diseases such as cancer and various genetic disorders," says CSHL Professor Adrian Krainer, Ph.D., who led the research. The study appears in the May 15 issue of Genes & Development.
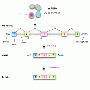
For a protein to be synthesized by the cell, the instructions encoded within that protein's gene have to be first copied from DNA into RNA. This initial copy, called a pre-messenger RNA, is then edited much like film footage, where the unnecessary bits—strings of nucleotides called introns—are snipped out and the remaining bits (called exons) are spliced together. For the cut-and-paste mechanism to work correctly, the cell's splicing machinery initially has to be guided to the correct splice site at the beginning of each intron on the target pre-mRNA by another, smaller RNA called U1.
U1 finds the right spots, or splice sites, by lining up against the target RNA and pairing its own RNA nucleotides or bases (the "letters" of the RNA code, A, U, C, G) with those of the target RNA such that its A nucleotide pairs with the target's U, and its C nucleotide pairs with the target's G nucleotide, or vice-versa. U1's ability to recognize splice sites at the beginning of introns is the strongest when up to 11 bases are paired up with their partners on the target RNA, but in most cases, fewer base pairs are formed
Two years ago, Krainer and postdoctoral researcher Xavier Roca discovered, however, that the U1 RNA could recognize even seemingly imperfect splice sites that did not appear to have the correct matching RNA sequence. Instead of lining up against the first RNA base of the target intron's RNA sequence, U1 can sometimes slide down the sequence to the next base if this shift will allow more of the U1 bases to pair up with the target's bases and thereby produce a stronger match.
Krainer and Roca have now found a second, and much more prevalent, alternative option. Instead of shifting away from the first base, they show using a combination of experimental and computational approaches that one or more bases on either U1 or its target can "bulge out"—or pull away from the lineup—if this allows the surrounding nucleotides to produce a stronger match between U1 and the target.
Based on studying splice sites in about 6,500 human genes, they estimate that up to 5% of all splice sites, present in 40% of human genes use this "bulge" mechanism to be recognized. Interestingly, some of these atypically recognized sites occur within genes which when mutated lead to disease, and others are sites where alternative splicing—allowing a single pre-mRNA to give rise to different proteins—can occur.
"This study expands what we thought were the rules for splice site recognition by U1," said Michael Bender, Ph.D., who oversees RNA processing grants at the National Institutes of Health's National Institute of General Medical Sciences (NIGMS), which partially supported the study. "By extending our understanding of how the splicing process works, the findings may help us pinpoint the splicing defects that underlie certain diseases and develop new therapeutics to treat them."
More information: "Widespread recognition of 5' splice sites by noncanonical base-pairing to U1 snRNA involving bulged nucleotides" appears in the May 15th issue of Genes & Development. The full citation is: Xavier Roca, Martin Akerman, Hans Gaus, Andrés Berdeja, C. Frank Bennett and Adrian R. Krainer. The paper can be downloaded at genesdev.cshlp.org/content/26/10/1098.full
Provided by Cold Spring Harbor Laboratory