This article has been reviewed according to Science X's editorial process and policies. Editors have highlighted the following attributes while ensuring the content's credibility:
fact-checked
trusted source
proofread
Potential applications of modern large language models in electrocatalysis
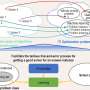
, serving as a conduit for communication between artificial intelligence and humans, can break down the barriers in this interaction. They overcome the limitations imposed by human's conventional thinking, absorbing knowledge from all subfields of catalysis while keeping up with efficient daily updates in literature. Thus, they fully leverage humanity's collective knowledge in catalysis, paving a smooth road for the quest for efficient catalysts. Credit: Chinese Journal of Catalysis")
Large language models, outstanding representatives of modern technology, have significant impacts on various fields of modern society. These models, constructed by billions of neurons, incorporate the extensive knowledge accumulated by humans so far, possessing the exceptional abilities to chat with people around the world fluently.
Their human-like intelligence enables them to tackle various challenges of modern society and shows great potential for applications in various fields.
Recently, a research team led by Prof. Ziyun Wang from the University of Auckland in New Zealand delved into the potential applications of large language models in the field of electrocatalysis. This Perspective aims to elucidate how these AI-driven models help researchers deepen their understanding of catalysis and advance intelligent catalyst design.
The work first examined the limitations of traditional experimental methods and multi-scale simulation approaches, such as high resource consumption, slow progress, and the constraints of human capabilities. The study then highlighted the significant advantages of large language models in electrocatalysis research.
These models can transcend human cognitive limits and theoretically accumulate unlimited knowledge. Despite their enormous potential, challenges such as balancing generalization and domain specificity, and text limitations remain.
To address these challenges, the paper, which appears in Chinese Journal of Catalysis, introduced the development of multimodal large language models and their specific applications in electrocatalysis research.
These applications include direct interaction with experimenters, continuous optimization based on experimental feedback, fine-tuning of pre-trained models, and multimodal data integration with visual encoders.
The paper emphasized the vast potential of multimodal large language models in areas such as spectral analysis, experimental pathway design, transition state search, molecular structure design, catalyst optimization, and problem diagnosis. In summary, multimodal approaches hold broad application prospects in catalysis, integrating various data sources to provide powerful tools and technical support for catalyst design, reaction mechanism research, and optimization of reaction conditions.
The work also discussed large language models' role and future development trends in scientific research. While these models have demonstrated outstanding capabilities in knowledge accumulation, they may still fall short in creating new knowledge compared to scientists. Large language models should be deeply integrated with experimental and simulation methods to enhance their predictive power and multimodal learning capabilities.
Such integration will enable large language models to more comprehensively assist researchers, thereby accelerating the development of scientific research. This development trend not only helps improve the efficiency and accuracy of scientific research but also brings more innovation and breakthroughs to the scientific community.
More information: Chengyi Zhang et al, Large language model in electrocatalysis, Chinese Journal of Catalysis (2024). DOI: 10.1016/S1872-2067(23)64612-1
Provided by Chinese Academy of Sciences