Scientists map what factors influence the news agenda
Computer scientists have analysed over a million news articles in 22 languages to pinpoint what factors, such as the Eurovision song contest, influence and shape the news agenda in 27 EU countries. This is the first large-scale content-analysis of cross-linguistic text using artificial intelligence techniques.
Every day hundreds of news outlets across Europe choose which story to cover from a wide and diverse selection. While each outlet may be making these choices based on individual criteria, clear patterns emerge when all these choices are studied over a large set of outlets and a long time.
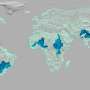
The international team of researchers is led by Nello Cristianini, Professor of Artificial Intelligence at the University of Bristol in conjunction with Professor Justin Lewis, Head of the School of Journalism, Media and Cultural Studies at Cardiff University. An article published in the issue of PLoS ONE (Dec. 2010), has discovered that the news content chosen reflects national biases, as well as cultural, economic and geographic links between countries. For example outlets from countries that trade a lot with each other and are in the Eurozone are more likely to cover the same stories, as are countries that vote for each other in the Eurovision song contest.
Deviation from "normal content" is more pronounced in outlets of countries that do not share the Euro, or have joined the EU later. The analysis the researchers have conducted could not have been done in the past, due to the sheer scale of the data, but is now possible using automated methods from artificial intelligence because of recent advances in machine translation and text analysis.
Professor Nello Cristianini from the University's Intelligent Systems Laboratory in the Faculty of Engineering said: "Automating the analysis of news content could have significant applications, due to the central role played by the news media in providing the information that people use to make sense of the world."
The researchers selected the top-ten news outlets, established by the volume of web traffic, for each of the 27 EU countries using the leading news feed of each or the main page of the news outlet. In total they gathered 1,370,874 news items from the top stories of the top outlets of each EU country for six months, from 1 August 2009 until 31 January 2010. The non-English language news items, 1.2 million, were translated automatically to English.
Several expected connections between countries were found such as Greece-Cyprus; Czech Republic-Slovakia; Latvia-Estonia; United Kingdom-Ireland; Belgium-France. Links between countries not explained by borders, trade or cultural relations, could be due to other factors and could be the basis of further research.
Professor Justin Lewis said: "This approach has the potential to revolutionise the way we understand our media and information systems. It opens up the possibility of analysing the mediasphere on a global scale, using huge samples that traditional analytical techniques simply couldn't countenance. It also allows us to use automated means to identify clusters and patterns of content, allowing us to reach a new level of objectivity in our analysis."
While this approach lacks qualitative analysis provided by people, this new research is a significant breakthrough in the study of media content especially due to the recent availability of millions of books and news articles in digital format.
Provided by University of Bristol