Molecular tweezer decodes polymer sequences: 'reading' molecule discovered at Reading
A team of chemists at the University of Reading, led by Professor Howard Colquhoun, have designed a system in which a tweezer-like molecule is able to recognise specific monomer sequences in a linear copolymer. As a result, and for the first time ever, sequence-information in a synthetic polymer has been ‘read’ by a mechanism which mirrors one of the processes on which life itself is based.
The discovery is described in two papers: Recognition of polyimide sequence information by a molecular tweezer (H.M. Colquhoun and Z. Zhu, Angewandte Chemie, International Edition, 2004, Issue 38, p. 5040) and Principles of sequence-recognition in aromatic polyimides (H.M. Colquhoun, Z. Zhu, C.J. Cardin and Y. Gan, Chemical Communications, 2004, Issue 23, p. 2650). These journals are regarded worldwide as the most important media for the publication of urgent communications on important new developments in the chemical sciences.
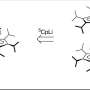
Professor Colquhoun and his colleague Dr Zhu designed the ‘tweezer’ so that it binds at particular sites along the polymer chain – namely, at the sequences which complement its own structure most closely. The researchers then used spectroscopic methods to show that the molecular tweezer can bind bind at both adjacent and non-adjacent sites along the polymer chain. From this evidence, the specific sequences present within the copolymer, which is made of several different structural units, could be clearly identified. A full and detailed picture of the way in which the tweezer binds to the polymer chain was finally obtained when Dr Zhu obtained crystals of a complex between the tweezer and a model oligomer and their structure was determined by Dr Cardin and Ms Gan.
“This is a unique system in which sequence-information in a polymer chain can be ‘read’ through sequence-selective interactions with small molecules,” said Professor Colquhoun. “As such, we believe that the ‘tweezer’ will represent a significant contribution to the eventual development of ultra-miniaturised information-storage and processing at the molecular level.
“Moreover, the principles of sequence-recognition emerging from this entirely synthetic system could help us develop an understanding of the way in which biological information-processing may have originated some three billion years ago. A paradoxical feature of information theory is that polymers with entirely random sequences (as in the copolymers we are working with) contain more potential information than any other type of polymer. Indeed, DNA itself appears at first sight to be an entirely random copolymer, in the sense that there are no rules governing the sequence of the bases. The sequence acquires meaning only though the operation of the genetic code, which is itself based on sequence-specific binding of small molecules to polymer chains. This observation, together with our own results, lead one to speculate that the earliest biological sequence-information may have originated as a (natural) selection from random monomer sequences occurring in a population of replicating co-polymers.”
In the future, the researchers hope to modify the tweezer so as to promote reaction between neighbouring molecules when these are bound to the polymer. This would mimic biological information-processing to an even greater extent, as sequence-information would then be copied into an entirely different type of molecule.
Source: University of Reading