Our brains are wired so we can better hear ourselves speak, study shows
")
(PhysOrg.com) -- Like the mute button on the TV remote control, our brains filter out unwanted noise so we can focus on what we're listening to. But when following our own speech, a new brain study from UC Berkeley shows that instead of one mute button, we have a network of volume settings that can selectively silence and amplify the sounds we make and hear.
Neuroscientists from UC Berkeley, UCSF and Johns Hopkins University tracked the electrical signals emitted from the brains of hospitalized epilepsy patients. They discovered that neurons in one part of the patients' hearing mechanism were dimmed when they talked, while neurons in other parts lit up.
Their findings, published today (Dec. 8, 2010) in the Journal of Neuroscience, offer new clues about how we hear ourselves above the noise of our surroundings and monitor what we say. Previous studies have shown a selective auditory system in monkeys that can amplify their self-produced mating, food and danger alert calls, but until this latest study, it was not clear how the human auditory system is wired.
"We used to think that the human auditory system is mostly suppressed during speech, but we found closely knit patches of cortex with very different sensitivities to our own speech that paint a more complicated picture," said Adeen Flinker, a doctoral student in neuroscience at UC Berkeley and lead author of the study.
"We found evidence of millions of neurons firing together every time you hear a sound right next to millions of neurons ignoring external sounds but firing together every time you speak," Flinker added. "Such a mosaic of responses could play an important role in how we are able to distinguish our own speech from that of others."
While the study doesn't specifically address why humans need to track their own speech so closely, Flinker theorizes that, among other things, tracking our own speech is important for language development, monitoring what we say and adjusting to various noise environments.
"Whether it's learning a new language or talking to friends in a noisy bar, we need to hear what we say and change our speech dynamically according to our needs and environment," Flinker said.
He noted that people with schizophrenia have trouble distinguishing their own internal voices from the voices of others, suggesting that they may lack this selective auditory mechanism. The findings may be helpful in better understanding some aspects of auditory hallucinations, he said.
Moreover, with the finding of sub-regions of brain cells each tasked with a different volume control job – and located just a few millimeters apart – the results pave the way for a more detailed mapping of the auditory cortex to guide brain surgery.
In addition to Flinker, the study's authors are Robert Knight, director of the Helen Wills Neuroscience Institute at UC Berkeley; neurosurgeons Edward Chang, Nicholas Barbaro and neurologist Heidi Kirsch of the University of California, San Francisco; and Nathan Crone, a neurologist at Johns Hopkins University in Maryland.
The auditory cortex is a region of the brain's temporal lobe that deals with sound. In hearing, the human ear converts vibrations into electrical signals that are sent to relay stations in the brain's auditory cortex where they are refined and processed. Language is mostly processed in the left hemisphere of the brain.
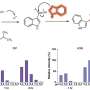
In the study, researchers examined the electrical activity in the healthy brain tissue of patients who were being treated for seizures. The patients had volunteered to help out in the experiment during lulls in their treatment, as electrodes had already been implanted over their auditory cortices to track the focal points of their seizures.
Researchers instructed the patients to perform such tasks as repeating words and vowels they heard, and recorded the activity. In comparing the activity of electrical signals discharged during speaking and hearing, they found that some regions of the auditory cortex showed less activity during speech, while others showed the same or higher levels.
"This shows that our brain has a complex sensitivity to our own speech that helps us distinguish between our vocalizations and those of others, and makes sure that what we say is actually what we meant to say," Flinker said.