New study shows the potential of DNA-based data-structures systems

Newcastle University research offers important insights into how we could turn DNA into a green-by-design data structure that organises data like conventional computers.
The team, led by researchers from Newcastle University's School of Computing, created new dynamic DNA data structures able to store and recall information in an ordered way from DNA molecules. They also analysed how these structures are able to be interfaced with external nucleic acid computing circuits.
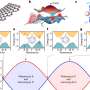
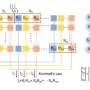
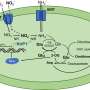
Publishing their findings in the journal Nature Communications, the scientists present an in vitro implementation of a stack data structure using DNA polymers. Developed as a DNA chemical reaction system, the stack system is able to record combinations of two different DNA signals (0s and 1s), release the signals into solution in reverse order, and then re-record.
The stack, which is a linear data structure which follows a particular order in which the operations are performed, stores and retrieves information (DNA signal strands) in a last-in first-out order by building and truncating DNA "polymers" of single ssDNA strands. Such a stack data structure may eventually be embedded in an in vivo context to store messenger RNAs and reverse the temporal order of a translational response, among other applications.
Professor Natalio Krasnogor, of Newcastle University's School of Computing, who led the study explains: "Our civilisation is data hungry and all that information processing thirst is having a strong environmental impact. For example, digital technologies pollute more than the aviation industry, the top 7000 data centers in the world use around 2% of global electricity and we all heard about the environmental footprint of some cryptocurrencies.
"In recent years DNA has been shown to be an excellent substrate to store data and the DNA is a renewable, sustainable resource. At Newcastle we are passionate about sustainability and thus we wanted to start taking baby steps into green-by-design molecular information processing in DNA and go beyond simply storing data. We wanted to be able to organise it. In computer science, data structures are at the core of all the algorithms that run our modern economy; this is so because you need a way to have a unified and standardised way to operate on the data that is stored. This is what data structures enable. We are the first to demonstrate a molecular realisation of this crucial component of the modern information age."
Information processing at the nanoscale level
Study co-author, Dr. Annunziata Lopiccolo, Research Associate at Newcastle University's Centre for Synthetic Biology and the Bioeconomy, added: "If we start thinking about data storage, immediately our minds picture electronic microchips, USB drives and many other existing technologies. But over the last few years biologists challenged the data storage media sector demonstrating that the DNA nature, as a highly stable and resilient media, can function as a quaternary data storage, rather than binary. In our work we wanted to demonstrate that it is possible to use the quaternary code to craft readable inputs and outputs under the form of programmable signals, with a linear and organised data structure. Our work expands knowledge in the context of information processing at the nanoscale level."
Study co-author Dr. Harold Fellermann, Lecturer at Newcastle University School of Computing, added: "Our biomolecular data structure, where both data as well as operations are represented by short pieces of DNA, has been designed with biological implementations in mind. In principle, we can imagine such a device to be used inside a living cell, bacteria for example. This makes it possible to bring computational power to domains that are currently hard to access with traditional silicon-based, electronic computing. In the future, such data structures might be used in environmental monitoring, bioremediation, green production, and even personalised nanomedicine."
Study co-author, Dr. Benjamin Shirt-Ediss, Research Associate, Newcastle University School of Computing, said: "It was really interesting to develop a computational model of the DNA chemistry and to see good agreement with experimental results coming out of the lab. The computational model allowed us to really get a handle on the performance of the DNA stack data structure—we could systematically explore its absolute limits and suggest future avenues for improvement."
The experimental DNA stack system constitutes proof-of principle that a polymerising DNA chemistry can be used as a dynamic data structure to store two types of DNA signal in a last-in first-out order. While more research is needed to determine the best-possible way to archive and access DNA-based data, the study highlights the enormous potential of this technology, and how it could help tackle the rapidly growing data demands.
More information: Annunziata Lopiccolo et al, A last-in first-out stack data structure implemented in DNA, Nature Communications (2021). DOI: 10.1038/s41467-021-25023-6
Journal information: Nature Communications
Provided by Newcastle University