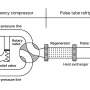
Measurement performed in an anechoic chamber. (Left) Photo of the metamaterial listener in the chamber. (Right) Schematic of the setup and two examples of synthesized word. (B) Measured transfer functions for the location of three speakers. Credit: Yangbo Xie, PNAS, doi: 10.1073/pnas.1502276112")
(A) Measurement performed in an anechoic chamber. (Left) Photo of the metamaterial listener in the chamber. (Right) Schematic of the setup and two examples of synthesized word. (B) Measured transfer functions for the location of three speakers. Credit: Yangbo Xie, PNAS, doi: 10.1073/pnas.1502276112
(Phys.org)—A team of researchers at Duke University has found a way to solve what is known as the cocktail party problem, getting a computer to pick out different human voices among multiple speakers in a single room. In their paper, published in Proceedings of the National Academy of Sciences they describe the device they constructed and the algorithm that goes along with it.
Most people have the uncanny ability to stand among a group of people, many of whom are talking, and pick out the words that are being spoken by any given individual, at will—our brains are somehow able to combine all the necessary ingredients—pitch, tone, distance, etc. and perhaps most importantly, filtering, to allow us to process only the words being spoken by the person we are focusing our attention on. Getting a computer to accomplish the same feat has been difficult—most solutions rely on the placement of multiple microphones, though some newer approaches have relied on artificial intelligence systems. Unfortunately, most such efforts have not led to a computer being anywhere near as accurate as a human being, until now.
The device developed by the team at Duke is made of plastic and is approximately pizza sized and shaped, thought it is a bit thicker—it was also constructed using a 3D printer. It is made up of 36 pie slices, or wedges, each made of a honeycombed structured acoustic metamaterial. Openings around the edges channel the sound toward a microphone that is fixed in the center of the hub. The wedges cause sound that passes through to be modified slightly in a beneficial way (attenuating certain frequencies). The sound that is captured by the microphone is then processed by an algorithm running on a computer that is able to localize what has been heard and assign words to a given speaker.

This prototype sensor can separate simultaneous sounds coming from different directions using a unique distortion given by the slice of "pie" that it passes through. Credit: Steve Cummer, Duke University
In testing their system, which the team describes as combining acoustic metamaterials and compressive sensing, they found it to be 96.7 percent accurate when run with three overlapping sound sources. They believe their device could be used in speech recognition applications and perhaps sensing or acoustic scenarios as well—and with some modifications, even in hearing aids.

The prototype sensor is tested in a sound-dampening room to eliminate echoes and unwanted background noise. Credit: Steve Cummer, Duke University
More information: Single-sensor multispeaker listening with acoustic metamaterials, Yangbo Xie, PNAS, DOI: 10.1073/pnas.1502276112
Abstract
Designing a "cocktail party listener" that functionally mimics the selective perception of a human auditory system has been pursued over the past decades. By exploiting acoustic metamaterials and compressive sensing, we present here a single-sensor listening device that separates simultaneous overlapping sounds from different sources. The device with a compact array of resonant metamaterials is demonstrated to distinguish three overlapping and independent sources with 96.67% correct audio recognition. Segregation of the audio signals is achieved using physical layer encoding without relying on source characteristics. This hardware approach to multichannel source separation can be applied to robust speech recognition and hearing aids and may be extended to other acoustic imaging and sensing applications.
Journal information: Proceedings of the National Academy of Sciences
© 2015 Tech Xplore