Rockefeller scientists first to reconstitute the DNA 'replication fork'
When a cell divides, it must first make a copy of its DNA, a fundamental step in the life cycle of cells that occurs billions of times a day in the human body. While scientists have had an idea of the molecular tools that cells use to replicate DNA—the enzymes that unzip the double-stranded DNA and create "daughter" copies—they did not have a clear picture of how the process works.
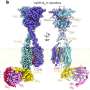
Now, researchers at Rockefeller University have built the first model system to decipher what goes on at the "replication fork"—the point where DNA is split down the middle in order to create two exact copies. The findings are specific to eukaryotic cells, the defining feature of which is that the DNA is contained within a nucleus. All multicellular life forms, including humans, are eukaryotes. The researchers' findings, which may have profound implications for the study of cell division and human disease, appeared July 6 in the journal Nature Structural and Molecular Biology.
"We were able to purify and reconstitute the central components that propel the eukaryotic replication fork, which for the first time enables us to study the process and its regulation by the cell in fine detail," says the paper's senior author Michael O'Donnell, head of the Laboratory of DNA Replication at Rockefeller University. "What is more exciting, I believe, is that this opens up replication-fork biology to biochemical study by many labs, providing a new tool to unravel some pressing questions in a number of fields of study, including epigenetics and DNA repair." O'Donnell is Anthony and Judith Evnin Professor at Rockefeller and a Howard Hughes Medical Institute investigator.
According to O'Donnell, the team's techniques may allow researchers to reconstruct at the molecular level biochemical events that are known to occur but were difficult or impossible to study in detail. For example, scientists know that epigenetic information—inheritable information that is not encoded by the DNA sequence, but instead lies in modifications to proteins associated with the DNA—is passed along to the daughter cells after DNA replication. Yet exactly how that occurs remains a mystery. Another unknown is what happens when the replication fork encounters an area of damaged DNA as it travels down the length of DNA.
"Diseases, such as cancer, often arise from DNA damage or defects in episomal inheritance, so these findings could have direct relevance to these fields," O'Donnell says. "There are plenty of hypotheses about the mechanics of DNA replication, but until now the process could not be studied using a defined system with pure proteins."
The replication fork is assembled as a complex of numerous proteins, one of which is an 11-subunit collective called CMG that unwinds and separates the DNA into two individual strands. The emerging replication fork looks much like a zipper opening, with CMG in the role of a zipper slider and the individual strand appearing like the two rows of teeth of the open zipper.
Each of these strands then becomes the templates for daughter copies. The act of synthesizing a new complementary strand to match the templates is performed by two different polymerase enzymes, which match each complementary subunit of DNA (the nucleotide "letters" that make up the genetic code) to the chain, resulting in a new double-stranded DNA molecule. These enzymes are known as polymerase epsilon (Pol epsilon) and polymerase delta (Pol delta), and the O'Donnell laboratory sought to examine how they attach to DNA to perform their task.
One of the chief features of the replications fork is its essential asymmetry. Because the two strands of double-stranded DNA are complementary, they fit together head to tail (in biochemical terms, the 5' end to the 3' end), so that the head of one strand is attached to the tail of the other. New DNA can only be synthesized in one direction (5' to 3'). This leads to a traffic problem of sorts, where the two daughter strands of DNA are created at slightly different paces, resulting in a leading strand (the work of Pol epsilon) and a lagging strand (Pol δ) being synthesized in opposite directions.
In order to study the replication fork, O'Donnell and his laboratory needed to recreate the process in a simple model. In a test tube, they brought together the essential enzymes with a set of nucleotides (DNA building blocks) and a linear molecule of duplex DNA.
Pol epsilon, they found, does not attach very well to the DNA on its own. It requires the presence of the CMG complex to attach securely. Even in an excess of Pol delta, CMG chose Pol epsilon without fail. Pol delta, however, binds very strongly to another accessory protein—the PCNA clamp—a ring shaped protein that encircles DNA. Only when the PCNA clamp is on the lagging strand does Pol delta strongly bind to PCNA. Even when the researchers added a 20 to 1 excess of Pol epsilon, PCNA only would work with Pol delta on a lagging strand model DNA.
"As a research tool, our model could allow scientists to better understand what occurs in DNA replication, and what goes wrong in disease states," O'Donnell says.
To create his replication fork model, O'Donnell used enzymes from yeast. Like human cells, yeast cells are eukaryotic, meaning a membrane encloses their nucleus. Prokaryotic cells, like bacteria, evolved a separate (although similar) method for replicating DNA. The eukaryotic machinery, from single-celled amoeba to humans, are remarkably conserved through evolution, which allows for high confidence that the replication fork model also represents what occurs in human cells.
"For much of my career, I studied the replication fork in prokaryotes, thinking that perhaps what I learned could be applied to create new types of antibiotics that would stop the replication process in its tracks," O'Donnell says. "Now I study the replication fork in eukaryotes in the hopes that what we find could be applied to fix the process and help it along in the case of human disease."
More information: Mechanism of asymmetric polymerase assembly at the eukaryotic replication fork, Nature Structural & Molecular Biology (2014) DOI: 10.1038/nsmb.2851
Journal information: Nature Structural & Molecular Biology , Nature Structural and Molecular Biology
Provided by Rockefeller University