Amino acid fingerprints revealed in new study

Some three billion base pairs make up the human genome—the floor plan of life. In 2003, the Human Genome Project announced the successful decryption of this code, a tour de force that continues to supply a stream of insights relevant to human health and disease.
Nevertheless, the primary actors in virtually all life processes are the proteins coded for by DNA sequences known as genes. For a broad spectrum of diseases, proteins can yield far more compelling revelations than may be gleaned from DNA alone, if researchers can manage to unlock the amino acid sequences from which they are composed.
Now, Stuart Lindsay and his colleagues at Arizona State University's Biodesign Institute have taken a major step in this direction, demonstrating the accurate identification of amino acids, by briefly pinning each in a narrow junction between a pair of flanking electrodes and measuring a characteristic chain of current spikes passing through successive amino acid molecules.
By using a machine learning algorithm, Lindsay and his team were able to train a computer to recognize bursts of electrical activity representing the momentary binding of an amino acid within the junction. The noise signals were shown to act as reliable fingerprints, identifying amino acids, including subtly modified variants.
Proteins are already providing a wealth of information pertinent to diseases including cancer, diabetes and neurological disorders like Alzheimer's, as well as furnishing key insights into another protein-mediated process: aging.
The new work advances the prospect of clinical protein sequencing and the discovery of new biomarkers—early warning beacons signaling disease. Further, protein sequencing may radically transform patient treatment, enabling precise monitoring of disease response to therapeutics, at the molecular level.
The group's research results are reported in the advanced online edition of the journal Nature Nanotechnology.
From genome to proteome
An enormous library of proteins—known as the proteome, occupies center stage in virtually all life processes. Proteins are vital for cellular growth, differentiation and repair; they catalyze chemical reactions and provide defense against disease, among myriad housekeeping functions.
One of the strangest surprises to emerge from the Human Genome Project is the fact that only about 1.5 percent of the genome codes for proteins. The rest of the DNA nucleotides form regulatory sequences, non-coding RNA genes, introns, and noncoding DNA, (once derisively labeled "junk DNA"). This leaves humans with a scant 20-25,000 genes, a sobering discovery given that the lowly roundworm has roughly the same number. As professor Lindsay notes, the news gets worse: "A lily plant has about an order of magnitude more genes than we do," he says.
The mystery of complex organisms like humans bearing an appallingly low gene number has to do with the fact that proteins generated from the DNA blueprint can be modified in a number of ways. In fact, scientists have already identified over 100,000 human proteins and researchers like Lindsay believe this may be only the tip of the iceberg.
Just as sentences can have their meanings altered through changes in word order or punctuation, proteins generated from gene templates can change function (or sometimes be rendered inoperable), often with serious consequences for human health. Two key processes that modify proteins are known as alternative splicing and post-translational modification. They are the drivers of the extraordinary protein variation observed.
Alternative splicing occurs when coding regions of RNA, (known as exons) are spliced together and non-coding regions (known as introns) are snipped out, prior to translation into proteins. This process does not always occur neatly, with occasional overlaps of exons or introns being introduced, producing alternatively spliced proteins, whose function may be altered.
Post-translational modifications are markers added after proteins have been made. There are many forms of post-translational modification, including methylation and phosphorylation. Some altered proteins perform vital functions, while others may be aberrant and associated with disease (or disease propensity). A number of cancers are associated with such protein errors, which are already used as diagnostic markers. Proper identification of such proteins however remains a grand challenge in biomedicine.
New sequences
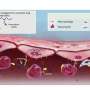
The technique described in the current research was earlier applied in the Lindsay lab for the successful sequencing of DNA bases. This method—known as recognition tunneling— involves threading a peptide through a tiny eyelet known as a nanopore. A pair of metal electrodes, separated by a gap of roughly two nanometers, sits on either side of the nanopore as successive units of a peptide are threaded through the tiny aperture, with each unit completing an electrical circuit and emitting a burst of current spikes.
The research group demonstrated that close analyses of these current spikes could enable researchers to determine which of the four nucleotide bases—adenine, thymine, cytosine or guanine—was poised between the electrodes in the nanopore.
"About 2 years ago in one of our lab meetings, it was suggested that maybe the same technology would work for amino acids," Lindsay says. Thus began efforts to tackle the substantially greater challenge of using recognition tunneling to identify all 20 amino acids found in proteins, as opposed to just 4 bases comprising DNA.
Single-molecule sequencing of proteins is of enormous value, offering the potential to detect diminishingly small quantities of proteins that may have been tweaked by alternative splicing or post-translational modification. Often, these are the very proteins of interest from the standpoint of recognizing disease states, though current technologies are inadequate to detect them.
As Lindsay notes, there is no equivalent in the protein world to polymerase chain reaction (PCR) technology, which allows minute quantities of DNA in a sample to be rapidly amplified. "We probably don't even know about most of the proteins that would be important in diagnostics. It's just a black hole to us because the concentrations are too low for current analytical techniques," he says, adding that the ability of recognition tunneling to pinpoint abnormalities on a single molecule basis "could be a complete game changer in proteomics."
The new paper describes a series of experiments in which pure samples of individual amino acids, individual molecules in mixed solution and finally, short peptide chains were successfully identified through recognition tunneling. The work sets the stage for a method to sequence individual protein molecules rapidly and cheaply (see accompanying animation).
A machine learning algorithm known as Support Vector Machine was used to train a computer to analyze the burst signals produced when amino acids formed bonds in the tunnel junction and emitted a lively noise signal as the poised electrodes passed tunneling current through each molecule. (The machine learning algorithm is the same one used by the IBM computer 'Watson' to defeat a human opponent in Jeopardy.)
Lindsay says that around 50 distinct signal burst characteristics were used in the amino acid identifications, but that most of the discriminatory power is achieved with 10 or fewer signal traits.
Remarkably, recognition tunneling not only pinpointed amino acids with high reliability from single complex burst signals, but managed to distinguish a post-translationally modified protein (sarcosine) from its unmodified precursor (glycine) and also to discriminate between mirror-image molecules knows as enantiomers and so-called isobaric molecules, which differ in peptide sequence but exhibit identical masses.
Pathway to the $1000 dollar proteome?
Lindsay indicates that the new studies, which rely on innovative strategies for handling single molecules coupled with startling advances in computing power, open up horizons that were inconceivable only a short time ago. It is becoming clear that the tools that made the $1000 genome feasible are equally applicable to an eventual $1000 dollar proteome. Indeed, such a landmark may not be far off. "Why not?" Lindsay asks. "People think it's crazy but the technical tools are there and what will work for DNA sequencing will work for protein sequencing."
While the tunneling measurements have until now been made using a complex laboratory instrument known as a scanning tunneling microscope (STM), Lindsay and his colleagues are currently working on a solid state device capable of fast, cost-effective and clinically applicable recognition tunneling of amino acids and other analytes. Eventual application of such solid-state devices in massively parallel systems should make clinical proteomics a practical reality.
More information: Single-molecule spectroscopy of amino acids and peptides by recognition tunneling, Nature Nanotechnology, DOI: 10.1038/nnano.2014.54
Journal information: Nature Nanotechnology
Provided by Arizona State University