100K genome project unveils 20 more foodborne pathogen genomes
The 100K Genome Project, led by the University of California, Davis, the U.S. Food and Drug Administration's Center for Food Safety and Applied Nutrition, and Agilent Technologies, today announced that it has added 20 newly completed genome sequences of foodborne disease-causing microorganisms to its public database at the National Center for Biotechnology Information.
The genomes were determined using Single Molecule, Real-Time (SMRT®) Sequencing technology from Pacific Biosciences of California, Inc.
This brings to 30 the number of genomic sequences completed by the 100K Genome Project, which aims to sequence the genomes of 100,000 bacterial and viral genomes. This genome sequencing effort is focused on speeding the diagnosis and treatment of foodborne diseases, as well as shortening the duration and limiting the spread of foodborne illness outbreaks. In the United States alone, foodborne diseases annually sicken around 48 million people and kill approximately 3,000, according to the Centers for Disease Control and Prevention.
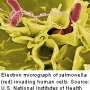
The newly deposited sequences include several isolates of Salmonella, Listeria, Campylobacter, and Vibrio, as well as a full characterization of their epigenomes – a diagnostic feature that defines how the DNA is chemically modified and changes how the organism behaves.
"These finished genome sequences represent the highest quality standard, with each strain closed in a single bacterial chromosome and the associated mobile DNA," said Bart Weimer, director of the 100K Genome Project and professor at the school of veterinary medicine at UC Davis. "They also contain complete associated phage or plasmid elements, which are critical for understanding pathogenicity, drug resistance and other biologically important traits that are linked to survival.
"The genomes we have analyzed to date are from pathogens responsible for common and debilitating foodborne infections," Weimer said, noting that the ready availability of this information will aid in reducing the time needed to diagnose and define outbreak strains.
"Making these genomic sequences publicly available through the National Center for Biotechnology Information database provides researchers and public health officials with information that will allow tracking of foodborne pathogens to their source," said Marc Allard, an FDA genomics expert and advisor to the 100K Genome Project. "This will ultimately speed outbreak investigations, reduce illness, and facilitate the development of new rapid test methods to detect pathogens."
The new genomes were sequenced and assembled using technology capable of detecting and identifying genome-wide methylation patterns as it performs DNA sequencing.
"Increasingly, microbiologists are recognizing that epigenetic information provides essential clues to the virulence of an outbreak strain," said Jonas Korlach, chief scientific officer at Pacific Biosciences. "The automated pipelines that made the completion of these 20 genomes and epigenomes possible serve as a solid foundation for the production of many more high-quality, finished genomes of foodborne pathogens through this project in the near future."
More information: www.ncbi.nlm.nih.gov/bioproject/186441
Provided by UC Davis