No need to prepare: New method to directly sequence small genomes without library preparation
(Phys.org)—For the first time, researchers sequenced DNA molecules without the need for the standard pre-sequencing workflow known as library preparation.
Using this approach, the researchers generated sequence data using considerably less DNA than is required using standard methods, even down to less than one nanogram of DNA; 500 times less DNA than is needed by standard practices.
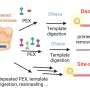
Libraries are collections of DNA fragments derived from genomic samples using molecular biology techniques specific to the sequencing technology being used. They are laborious, time consuming, and often DNA consuming. This new technique has the potential to greatly reduce DNA consumption and the time it takes to generate sequencing data from small genomes.
"This is the first time that anyone has been able to directly sequence single molecules of DNA in this way." says Dr Paul Coupland, first author from the Wellcome Trust Sanger institute. "We applied our approach to sequencing the genomes of viruses and bacteria and found that even with a relatively low level of optimisation, we were able to determine what organisms we were looking at, whether specific genes or plasmids were present in the sample (which can be important in determining antibiotic resistance) as well as other information such as modifications to specific DNA bases.
"Once optimised, our technique has great potential for a fast and efficient way of identifying organisms in hospitals and other healthcare settings. It also gives us the absolute confidence there is no library based bias in the sequence data, quite simply because no library was ever created."
The team utilised the PacBio RS, a sequencing system that sequences single molecules of DNA, for the direct sequencing approach. Sequence data was generated from small circular single-stranded and double-stranded DNA viral genomes, as well as from linear fragments covering the entire genome of an MRSA strain of Staphylococcus aureus.
The team tried analysing the genome of one organism using only eight hundred picograms of DNA, over six hundred times less than the quantity used in standard practice. In this example, the PacBio only generated 70 reads, or fragments of sequence, from the genome. Although this is a fraction of the number of reads generated relative to standard library methods, it was still enough information for the team to identify the specific organism being sequenced; this work could allow the identification of organisms in metagenomic samples that were previously undetectable.
"To sequence microorganisms, one needs to be able to grow them in a lab first," says Dr Tamir Chandra, lead author from the Babraham Institute. "Not only is this time consuming, but sometimes micro-organisms do not grow, making it extremely difficult to sequence their genome.
"With this method we can directly sequence these organisms and find out their identity in a short space of time."
"Our role at the Sanger Institute is to determine how we can utilise and improve these sequencing platforms to generate biological information more efficiently and in turn, possibly, influence the control and treatment of disease and infections." says Dr Harold Swerdlow, lead author from the Wellcome Trust Sanger Institute. "Our technique can be performed without any prior knowledge of the sequence and with no organism specific reagents, in a short space of time. This makes it a promising alternative for clinical situations such as infection control."
More information: Paul Coupland, Tamir Chandra, Mike Quail, Wolf Reik, Harold Swerdlow (2012). 'Direct sequencing of small genomes on the Pacific Biosciences RS without library preparation' Published in BioTechniques on 11 December 2012. www.biotechniques.com/article/113962
Provided by Wellcome Trust Sanger Institute