Signatures of selection inscribed on poplar genomes

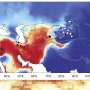
One aspect of the climate change models researchers have been developing looks at how plant ranges might shift, and how factors such as temperature, water availability, and light levels might come into play. Forests creeping steadily north and becoming established in the thawing Arctic is just one of the predicted effects of rising global temperatures.
A recent study published online August 24, 2014 in Nature Genetics offers a more in-depth, population-based approach to identifying such mechanisms for adaptation, and describes a method that could be harnessed for developing more accurate predictive climate change models. For the U.S. Department of Energy, which is developing biomass crops for biofuels production, this knowledge could determine which genotypes – genetic makeup of an organism – of biomass crop may thrive better than others in certain environments. The team led by Gerald Tuskan of Oak Ridge National Laboratory (ORNL), the Department of Energy Joint Genome Institute (DOE JGI) and Stephen DiFazio of West Virginia University, used a combination of genome-wide selection scans and analyses to understand the processes involved in shaping the genetic variation of natural poplar (Populus trichocarpa) populations.
As part of this long-term study, the team took samples from 1,100 poplar trees growing in wild populations in California, Oregon, Washington and British Columbia. They then clonally propagated (through cuttings) these trees in three plantations in California and Oregon. For their analyses, they pared the group down to 544 unrelated individuals whose genotypes could be accurately determined so as to characterize the genetic basis for variation in adaptation. The shift from an approach focused on single candidate genes to the large-scale computational approach analyzing all of them is made possible by the availability of the poplar genome, which was published in the journal Science in 2006 by the DOE JGI. Since the genome was made publicly available, it has been used to understand woody perennial plant development and served as a model for genome-level insights in forest trees. The publication itself has been cited more than 1,000 times in a wide variety of journals.

"This is the first time that deep genomics resources have ever been applied to an ecological question, in this case: 'What does selection do at the genome level?'" said Tuskan. "In the past, people looked at adaptation to factors such as temperature and light levels, and they examined variation in those genes as they vary across environmental gradients. There was a preconceived notion and a very narrow view of what was causing the response. Here, we took five major approaches, applied them blindly to the whole genome, and let the analysis show us where the fingerprints of selection are and what genes fall under those fingerprints." Watch a video of Tuskan on the importance of selection in trees below:
Going from 1,000 genotypes and 45,000 genes "to figuring out what's not just statistically significant but biologically meaningful" wasn't easy, said study first author Luke Evans of West Virginia University. "We did it by determining selection targets – things that looked like they might be under natural selection in wild populations and looked at growth and performance evidence that they affect adaptive traits. If these targets showed not only computational evidence of selection but also influenced phenotypes, it was a nice sort of dovetailing that was mutually supportive."
DiFazio highlighted the significance of the computational work. "Our approach is particularly powerful because we are mining standing natural variation resulting from tens of thousands of years of evolution and selection such that the alleles or gene variants that we have identified have great promise to provide robust, long-term improvements to biofuel feedstocks."
Evans also noted that their study yielded nearly 18 million single base pair variants of DNA sequence (called "SNPs") in poplar. These data can be accessed at Phytozome, DOE JGI's plant comparative genomics portal. "That's a massive number of naturally occurring variants, a lot in cell wall chemistry genes and other known productivity genes. This provides an immediate resource for tree breeding programs," he said.
The team identified 397 genomic regions that contribute to adaptive traits for wild populations of poplars. For example, data gathered on height, spring bud flush and fall bud set from the clonally-replicated poplars growing in three plantations indicated that in warmer climates, trees with earlier bud flush and later bud set were favored.
Given the importance of poplar trees, not just for their role in the ecosystem, for instance, in capturing carbon, but also for their economic importance in fields ranging from timber to bioenergy, Evans noted that the ability to have plantations of poplars through vegetative propagation is a significant tree-breeding tool for picking the appropriate stocks for the task. "If you know every base in a genome, you can skip whole generations and use genomic information to predict how well an individual will do," he said. "Plantations serve as the initial tests where you can take that genomic information and calibrate those predictions. With those reference points, you can scale everything."
More information: Population genomics of Populus trichocarpa identifies signatures of selection and adaptive trait associations, Nature Genetics, dx.doi.org/10.1038/ng.3075
Journal information: Nature Genetics
Provided by DOE/Joint Genome Institute